Now we have reviewed the basics of Roslyn it´s time to starting to describe its basic entities, let´s start with Syntax Trees
Syntax Trees
Syntax Trees are textual representations of source code in a tree view according to specific language specification. Syntax Trees represent the given object model for source code and is the basis on which we will perform a whole bunch of operations related with new compilation framework. It´s commonly said that Syntax Tree is a full fidelity representation of source code; this means that the tree is invertible.
All starts with the parser which is the responsible of transforming the code into a sequence of tokens, commonly known inside Roslyn world as Syntax Tokens.
Syntax tokens are all the atomic syntax elements that appears at source code, these are commonly referred to Identifiers, Keywords like “class”, “private”, “while” or “void”, Operators like “+”, etc.… and also all these phantom items or elements that don´t change the meaning of the code like whitespaces, tabs, and comments; all of them are known as Trivia tokens or Trivia nodes. So at the first stage the Parser will emit a complete sequence of syntax tokens.
Every syntax token is associated with an half-open interval element known as span, this is needed for knowing the specific token location at source code map for common task like highlighting code due to error or warnings for instance.
Syntax tokens are grouped into a more friendly language constructs that models common elements in language specifications, these items are the Syntax Nodes. Common canonical examples of syntax nodes are declaration of types and members, expressions, statements, etc.…Syntax nodes forms a rich object model which provides specialized types for every intermediate level syntax node; examples of these are, among others : SimpleMemberAccessExpression, Argument, AgumentList, ParamenterList, InvocationExpression, ExpressionStatement, etc.…
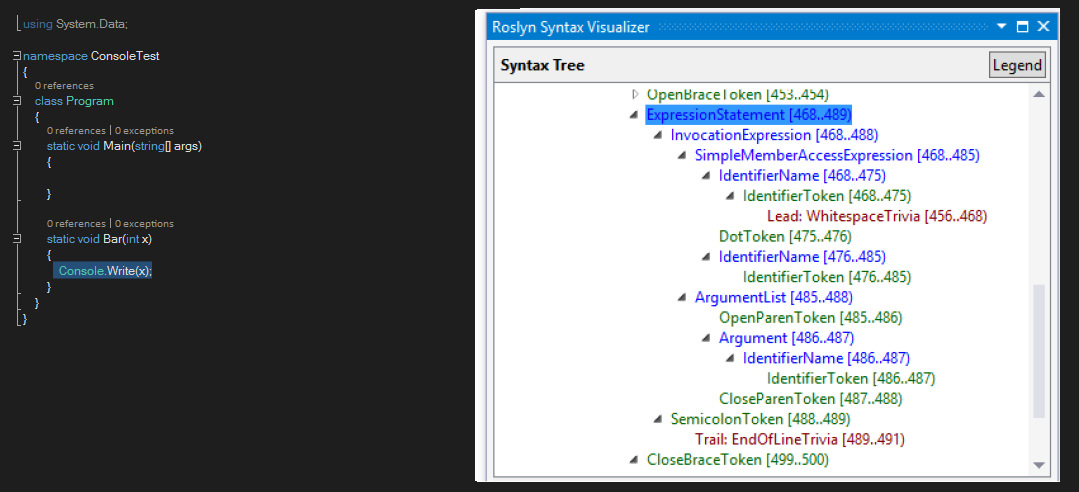
So we can argue that every syntax tree is a hierarchical collection of syntax nodes. To us, it´s possible to visualize this tree in parallel view to our code by using the Syntax Visualizer tool that can be found as a part of .Net Compiler Platform SDK as a Visual Studio plug-in. Even more Syntax Visualizer allows deep code analysis. You can download this extension for visual studio here
Syntax Visualizer provides a lot of information for every syntax node and syntax token and it´s very tolerant to incomplete code helping with debugging tasks. It implements a legend of colours for element identifications:
- Blue –> Syntax Node
- Green –> Syntax Token
- Red –> Syntax Trivia
- Pink-> Diagnostic
There are two way for navigating the tree at Syntax Visualizer: By clicking at syntax tree inside the visualizer or by directly clicking at your source code. In this moment the visualizer will highlight the node at the tree that corresponds to the code. It’s even possible to load the graphical representation of syntax tree or even a specific syntax node by using the View Directed Syntax Graph
Syntax Tree Properties
So in summary there are some key Syntax Tree properties that have to be highlighted:
- Syntax Trees provides an exact representation of source code by providing a complete set of information for dealing with all code items, which include spans that determine the location of every token
- Syntax Trees are robust and tolerant to absence of code: When the code you wrote is not complete, the syntax tree is able to create missing tokens for completion in meantime you finish to write the code, this tokens appears with the IsMissing property equals to true
- Syntax Trees are immutable and thread-safe, this provides a robust basis for asynchronously operations, so we can avoid managing locks and throttling. If a new token is added or modified a new copy is created to the tree you are working with never change, this is also important when we are performing refactoring operations.
- Syntax Trees Utilities: It´s possible to walk through, transform and traverse syntax trees in different ways thanks the rich object model, and special utilities like visitors, syntax walkers, etc.…
- Syntax Trees provides a connatural object model in line with the language specification of C# and Visual Basic, so it´s easy to build you own rich tools
More about Syntax Trees: Creation
Inside Roslyn object model SyntaxTree is an abstract class from which CSharpSyntaxTree and VisualBasicSyntaxTree are derived. These are the specialized classes for each language and expose simple methods for creating syntax trees: Create() and ParseText()



using System;
using System.Collections.Generic;
using System.Collections.Immutable;
using System.Diagnostics;
using System.Text;
using System.Threading;
using System.Threading.Tasks;
using Microsoft.CodeAnalysis.CSharp.Syntax;
using Microsoft.CodeAnalysis.Text;
using Roslyn.Utilities;
using InternalSyntax = Microsoft.CodeAnalysis.CSharp.Syntax.InternalSyntax;
namespace Microsoft.CodeAnalysis.CSharp
{
/// <summary>
/// The parsed representation of a C# source document.
/// </summary>
public abstract partial class CSharpSyntaxTree : SyntaxTree
{
internal static readonly SyntaxTree Dummy = new DummySyntaxTree();
public new abstract CSharpParseOptions Options { get; }The most simple way of creating a syntax tree is by using the ParseText() method of SyntaxTree class
var tree = CSharpSyntaxTree.ParseText(@"
public class DummyClass
{
public void DummyMethod(string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
HtmlNode header = doc.GetElementbyId("header");
return header.OuterHtml;
}
}");We can explore some alternative for creating syntax tree by using SyntaxFactory class which lives at Microsoft.CodeAnalysis library. SyntaxFactory allows to directly create every syntax token by using the rich compilation object model.
In addition, thanks its fluent syntax is possible to concatenate every syntax node creation. The use the SyntaxFactory is usually so elaborated and verbose that it´s preferable to use the Roslyn Code Quoter which simplifies the process.
Here the equivalent above code in terms of SyntaxFactory elements
CompilationUnit()
.WithMembers(
SingletonList<MemberDeclarationSyntax>(
ClassDeclaration("DummyClass")
.WithModifiers(
TokenList(
Token(SyntaxKind.PublicKeyword)))
.WithMembers(
SingletonList<MemberDeclarationSyntax>(
MethodDeclaration(
PredefinedType(
Token(SyntaxKind.VoidKeyword)),
Identifier("DummyMethod"))
.WithModifiers(
TokenList(
Token(SyntaxKind.PublicKeyword)))
.WithParameterList(
ParameterList(
SingletonSeparatedList<ParameterSyntax>(
Parameter(
Identifier("url"))
.WithType(
PredefinedType(
Token(SyntaxKind.StringKeyword))))))
.WithBody(
Block(
LocalDeclarationStatement(
VariableDeclaration(
IdentifierName("HtmlWeb"))
.WithVariables(
SingletonSeparatedList<VariableDeclaratorSyntax>(
VariableDeclarator(
Identifier("web"))
.WithInitializer(
EqualsValueClause(
ObjectCreationExpression(
IdentifierName("HtmlWeb"))
.WithArgumentList(
ArgumentList())))))),
LocalDeclarationStatement(
VariableDeclaration(
IdentifierName("HtmlDocument"))
.WithVariables(
SingletonSeparatedList<VariableDeclaratorSyntax>(
VariableDeclarator(
Identifier("doc"))
.WithInitializer(
EqualsValueClause(
InvocationExpression(
MemberAccessExpression(
SyntaxKind.SimpleMemberAccessExpression,
IdentifierName("web"),
IdentifierName("Load")))
.WithArgumentList(
ArgumentList(
SingletonSeparatedList<ArgumentSyntax>(
Argument(
IdentifierName("url")))))))))),
LocalDeclarationStatement(
VariableDeclaration(
IdentifierName("HtmlNode"))
.WithVariables(
SingletonSeparatedList<VariableDeclaratorSyntax>(
VariableDeclarator(
Identifier("header"))
.WithInitializer(
EqualsValueClause(
InvocationExpression(
MemberAccessExpression(
SyntaxKind.SimpleMemberAccessExpression,
IdentifierName("doc"),
IdentifierName("GetElementbyId")))
.WithArgumentList(
ArgumentList(
SingletonSeparatedList<ArgumentSyntax>(
Argument(
LiteralExpression(
SyntaxKind.StringLiteralExpression,
Literal("header"))))))))))),
ReturnStatement(
MemberAccessExpression(
SyntaxKind.SimpleMemberAccessExpression,
IdentifierName("header"),
IdentifierName("OuterHtml")))))))
.WithCloseBraceToken(
MissingToken(SyntaxKind.CloseBraceToken))))
.NormalizeWhitespace()From a performance point of view the first approach usually is faster than the second one when we are dealing with a common size of methods that are in fact simple ones, but when we have a great number of complex methods we can conclude that SyntaxFactory is usually preferable.
Analysing Syntax Trees
As we commented before syntax trees are a full fidelity code representation that means the basis over which all compilation operations are performed. In this line, Roslyn APIs provides several ways to manipulate and traverse threes, more specifically:
- By using the Object Model
- By using Query Methods
- By using Visitors
Let´s see a brief sample for each of them:
By using the Object Model
The first approach take the object model but to be honest this is not the most effective way to rescue nodes from a given tree. We typically start by getting the root (CompilationUnitSyntax) and then we need to check every node by using SyntaxKind.Enum in order to find using directives, namespaces, members, interfaces, etc…. and after descent into members to find declarations
var tree = CSharpSyntaxTree.ParseText(@"
public class DummyClass
{
public void DummyMethod(string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
HtmlNode header = doc.GetElementbyId("header");
return header.OuterHtml;
}
}");
var root =(CompilationUnitSyntax) tree.GetRoot();
foreach (var item in root.Members)
{
if (item.CSharpKind() == SyntaxKind.ClassDeclaration)
{
var @class = (ClassDeclarationSyntax) item;
foreach (var subItem in @class.Members)
{
If (subItem.CSharpKind() == SyntaxKind.MethodDeclaration)
{
var method =(MethodDeclarationSyntax) subItem;
// etc….
}
}
}
}By using the Query Methods
This is a more efficient alternative for traversing and selecting nodes from syntax trees. Due to the fact that many Roslyn APIs methods return an IEnumerable<T> where T can be SyntaxNode, SyntaxToken, etc.. it´s perfectly possible to use all the power of LINQ to Objects for selecting nodes from a given syntax tree. An example of this can be seen as DescendantNodes property from CompilationUnitSyntax class. Here we can see a brief example
var tree = CSharpSyntaxTree.ParseText(@"
public class DummyClass
{
public void DummyMethod(string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
HtmlNode header = doc.GetElementbyId("header");
return header.OuterHtml;
}
}");
var root =(CompilationUnitSyntax) tree.GetRoot();
var dummyClass = root.DescendantNodes().OfType<ClassDeclarationSyntax>().First(o => o.Identifier.Text == “DummyClass”);By using Visitors
Visitors are the standard pattern for traversing syntax trees, they are based on a more sophisticated mechanism know as double-dispatch. If we take a look to the SyntaxNode implementation we will find an Accept method which takes a Visitor object as parameter, if we are under C# environment we will deal with CSharpSyntaxNode and CSharpSyntaxVisitor
using System;
using System.Collections.Generic;
using System.Collections.Immutable;
using System.Diagnostics;
using System.IO;
using System.Linq;
using System.Reflection;
using System.Threading;
using Microsoft.CodeAnalysis.CSharp.Syntax;
using Roslyn.Utilities;
namespace Microsoft.CodeAnalysis.CSharp
{
public abstract partial class CSharpSyntaxNode : SyntaxNode, IMessageSerializable
{
internal CSharpSyntaxNode(GreenNode green, SyntaxNode parent, int position)
: base(green, parent, position)
{
}
…………..
public abstract TResult Accept<TResult>(CSharpSyntaxVisitor<TResult> visitor);
public abstract void Accept(CSharpSyntaxVisitor visitor);
/// <summary>
/// The node that contains this node in its Children collection.
/// </summary>
internal new CSharpSyntaxNode Parent
{
get
{
return (CSharpSyntaxNode)base.Parent;
}
}On the other hand, visitors can also use syntax nodes, in fact the CSharpSyntaxVisitor type exposes a Visit method which takes a CSharpSyntaxNode and other overloads for specific nodes, more specifically:
using Microsoft.CodeAnalysis.CSharp.Symbols;
using Microsoft.CodeAnalysis.CSharp.Syntax;
using Microsoft.CodeAnalysis.Text;
using Roslyn.Utilities;
namespace Microsoft.CodeAnalysis.CSharp
{
/// <summary>
/// Represents a <see cref="CSharpSyntaxNode"/> visitor that visits only the single CSharpSyntaxNode
/// passed into its Visit method and produces
/// a value of the type specified by the <typeparamref name="TResult"/> parameter.
/// </summary>
/// <typeparam name="TResult">
/// The type of the return value this visitor's Visit method.
/// </typeparam>
public abstract partial class CSharpSyntaxVisitor<TResult>
{
public virtual TResult Visit(SyntaxNode node)
{
if (node != null)
{
return ((CSharpSyntaxNode)node).Accept(this);
}
// should not come here too often so we will put this at the end of the method.
return default(TResult);
}
public virtual TResult DefaultVisit(SyntaxNode node)
{
return default(TResult);
}
}There is a simple implementation of Visit method that returns void and that is perfect for analysing the presence of specific types. In the same line, there exists more flavours of derived visitors like CSharpSyntaxWalker that can be used for special tasks like analysing the comments, etc.. or even the CSharpSyntaxRewriter that can is very useful when delating with code-transformations
That´s all by now, hope this helps
See you on the road