Overview
At this new microservices article we will discuss the concept of data and its impact on our microservices architecture design. Data consistency refers to the state where all data related to an event within our system remains consistent. Our main goal is to achieve data consistency in our system, both in ideal scenarios and under varying conditions.
Example
For instance, when a customer places an order on our website, we need to update the stock levels, create delivery records, and send confirmation emails. These actions are triggered by a single event in the new system, which involves placing an order. Under normal circumstances, we can successfully send the email, update the stock, and create the order record.
However, there may be situations where things don’t go as planned. For example, when checking the stock levels, you might discover insufficient stock, requiring the order to be canceled. Even in such cases, data consistency is crucial. The records associated with the order must either be undone or updated to reflect the cancellation.
Traditionally, handling events within a system involved treating the entire event, along with all associated data updates and creations, as a single transaction. Transactions group all data operations together, allowing for successful commits when all operations within the transaction are completed. In case of any failure, the entire transaction can be rolled back, reverting all data changes associated with that transaction.
Implementing the transaction mechanism in traditional monolithic systems was relatively straightforward because all the required data resided in a single, unified database. This centralized data approach made it easier to lock the data and ensure consistency using concurrency mechanisms.
aT mICROSERVICES
However, when it comes to microservices architecture, implementing transactions can be complex. This is because our system now consists of a distributed architecture with multiple components and services, each performing different functions. Furthermore, not only is your architecture distributed, but your data is also distributed. So, when you place an order, the data associated with that order is spread across multiple services. Consequently, you have to interact with multiple services to update the data related to the order. For example, you might communicate with an order service to create the order record, a stock service to check and update stock levels, and an email service to generate the email confirmation record. The entire transaction for an order is now distributed across the architecture.
In a microservices architecture, executing a distributed transaction heavily relies on the network infrastructure. This reliance introduces significant impacts on the transaction process.
For example, if there were inadequate stock levels, the transaction would need to be rolled back. However, with the involvement of the network infrastructure, there is an added risk. When checking the stock levels, the stock service may not be accessible due to a network issue. In such cases, the transaction needs to be handled and rolled back appropriately to ensure data consistency, such as canceling the order.
The CAP theorem, which states that network failures are inevitable, becomes particularly relevant in distributed systems. When designing transactions within such a system, one must consider the trade-off between data availability and data consistency.

At this article , we will explore patterns that help guarantee data consistency in your microservices architecture. However, it is essential to understand that these patterns often require making compromises between availability and consistency. Each pattern we introduce will emphasize the specific compromises made to achieve data consistency within your microservices architecture
CAP Theorem Briefing
The CAP theorem is a fundamental principle in distributed computing that identifies trade-offs between three desirable properties: Consistency, Availability, and Partition Tolerance. The theorem is named CAP, representing the first letters of these three properties, and it states that a distributed system can only satisfy two out of these three properties at the same time. Here’s a breakdown of these properties:
- Consistency: Every read operation from the system returns the most recent write. This property ensures that all nodes see the same data at the same time. An example of a consistent system is a single-node database. The CAP theorem’s consistency is equivalent to linearizability or atomic consistency, which is a very strong form of consistency.
- Availability: Every request to the system returns a response (without any error) about whether it succeeded or failed. This property ensures that the system remains operational and responsive despite failures.
- Partition Tolerance: The system continues to function despite network partitions or message loss. A network partition is a communication break within the system, typically due to a network outage, where a group of nodes can’t communicate with one or more other nodes.
While it might seem ideal to strive for all three properties, the CAP theorem states that in any given distributed system, you can only guarantee two out of the three in the presence of a network partition.
- A system that chooses consistency over availability is described as CP. When a partition occurs, it stops serving requests rather than returning potentially incorrect data.
- A system that chooses availability over consistency is described as AP. It continues to serve requests when a partition occurs, but the data might not be the latest.
- It’s important to note that no system can discard partition tolerance since network partitions can occur due to unavoidable reasons like network failures, hardware issues, etc. So, in real-world distributed systems, the trade-off is usually between consistency and availability when a network partition occurs.
In the context of microservices architecture, understanding the CAP theorem is important because it helps design services that meet specific application needs and handle inconsistencies and failures more effectively.
traditional transactions in Legacy monolithic systems
Traditional transactions aim to have the following characteristics: atomicity, consistency, isolation, and durability.
- Atomicity means that a transaction is either fully committed or fully rolled back, ensuring the data remains in a consistent state regardless of the transaction’s outcome. For example, if a transaction fails due to date or network issues, the entire transaction should be rolled back, preserving data consistency as if the transaction never occurred.
- Consistency ensures that a transaction transitions data from one valid state to another valid state. It emphasizes that a partially completed transaction should not leave the database in an incomplete state; instead, the transaction is rolled back to the previous valid state.
- Isolation requires that transactions, whether executed concurrently or sequentially, produce the same result. Each transaction is isolated and does not interfere with others, maintaining consistency in the overall system.
- Durability guarantees that once a transaction is committed, all associated data changes are permanently stored in the database. Even if the database powers off, the committed transaction remains intact, ensuring data durability.
Understanding these characteristics of traditional transactions, which are prevalent in systems with a single database, is crucial because when considering options for achieving data consistency in a microservices architecture, some of these characteristics may be compromised.
Data Consistency Patterns at Microservices
The first pattern we will review is the Two-Phase Commit pattern. It aims to deliver the core characteristics of a traditional transaction while prioritizing consistency over availability, aligning with the principles of the CAP theorem. Later in the module, we will explore how to implement the Two-Phase Commit pattern within our microservices architecture and discuss the drawbacks it introduces.
We will then delve into the Saga pattern, which also aims to achieve most of the ACID transaction properties but trades atomicity for availability and consistency. We will explore the implementation details of the Saga pattern and its impact on microservices architecture.
Finally, we will explore the Eventual Consistency pattern, which compromises some ACID transaction properties to prioritize availability over consistency. As the name suggests, this pattern eventually achieves consistency in terms of data but prioritizes availability over consistency, aligning with the principles of the CAP theorem.
Two-Phase Commit pattern
Two-Phase Commit pattern can be utilized to achieve data consistency in a microservices architecture. This pattern is specifically designed for distributed transactions, aiming to provide reliability comparable to traditional transactions and preserve ACID properties. The Two-Phase Commit pattern employs a transaction manager responsible for coordinating the transaction. The transaction manager ensures that all microservices involved can execute their respective parts of the transaction. It achieves this through a two-step process.
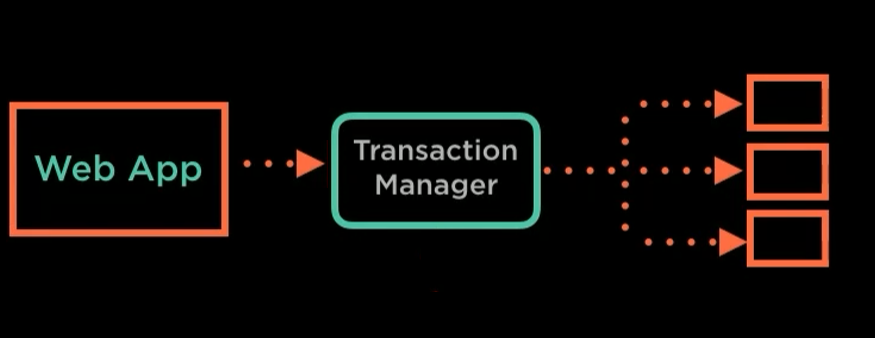
Prepare Phase
- The transaction manager initiates the prepare phase, instructing the involved services to prepare for processing the transaction.
- Each service determines if it can successfully carry out its part of the transaction.
- The prepare phase concludes with a voting phase, where services send their votes to the transaction manager indicating whether they can fulfill their obligations.
Commit Phase
- If the transaction manager receives a positive vote from all participating services, indicating they can proceed, it issues a commit instruction.
- The commit instruction prompts services to finalize their part of the transaction, committing the changes to their respective databases.
- This ensures data consistency within the microservices architecture.
However, if any of the services respond with a negative vote during the voting phase, indicating they cannot fulfill their part, the transaction manager issues a rollback command. The rollback command instructs all services to undo the preparations made during the prepare phase, such as releasing locks and reverting any changes.
While the Two-Phase Commit pattern may seem ideal for microservices architecture, there are caveats that make it less suitable in practice. These challenges include:
- Reliance on the Transaction Manager:
- The transaction manager becomes a single point of failure. Its availability is crucial for transaction processing.
- Transaction manager state maintenance is necessary, raising concerns about scalability.
- Unresponsive Services: If a service fails to respond during the voting phase, the transaction manager faces the dilemma of waiting for a timeout.
- Commit Failures: There is a possibility of services returning positive votes during the prepare phase but failing to commit the transaction successfully.
- Resource Locking: Services may need to lock resources during the prepare phase, potentially leading to reduced system performance due to excessive locking.
- Implementation Complexity: Proper implementation of the pattern is challenging, and it is recommended to use existing off-the-shelf solutions rather than creating custom versions.
- Scalability: Scaling out the transaction manager and ensuring coordination across multiple service instances present challenges.
- Reduced Throughput: The preparation and voting phases in the pattern can slow down the overall throughput of the system.
Considering these caveats, the Two-Phase Commit pattern emerges as more of an anti-pattern for microservices architecture. It poses difficulties in scaling and can reduce overall throughput, contradicting the objectives of microservices architecture. While it offers some advantages in terms of achieving traditional transaction-like performance with ACID properties, it is advisable to use this pattern only at a small scale. Instead, consider alternative patterns for achieving data consistency in your microservices architecture.
Saga pattern
Let’s explore how the Saga pattern can be utilized to achieve data consistency in a microservices architecture. The Saga pattern replaces the concept of a distributed transaction with a saga, breaking down the transaction into multiple requests that form the saga. Each of these requests can be seen as a sub-transaction contributing to the overall saga. The Saga pattern introduces a mechanism called the Saga Log to track the success or failure of each request.
When comparing the Saga pattern as a transaction-handling solution to the traditional approach using the ACID model, we compromise the atomicity property of a conventional transaction. Instead of having a single transaction grouping all related data changes triggered by an event, we end up with multiple requests forming a saga.
The Saga pattern has been around since 1987 and was initially described as a pattern for handling transactions within a single database. In the context of microservices, it has been adapted to help achieve data consistency across the architecture. However, the Saga pattern offers more than just transaction handling. It also serves as a failure management pattern. It provides features to handle request failures caused by either data issues or service failures. One of the key features of the Saga pattern is the ability to compensate requests. When a request fails or needs to be rolled back, a compensation request can be sent to undo the work performed by the original request and any completed requests. This way, if a saga fails, compensation requests are sent for preceding requests to undo their effects.
Implementing the Saga pattern requires a Saga Log, which records the start of a saga, the initiation and completion of requests, and the start and end of compensation requests. It also marks the overall saga’s completion. The component responsible for processing the saga and sending out the requests is called the Saga Execution Coordinator. This coordinator reads the Saga Log, updates it as the saga progresses, and manages the sending and receiving of requests. In case of failures, it also triggers the relevant compensation requests for any failed requests.
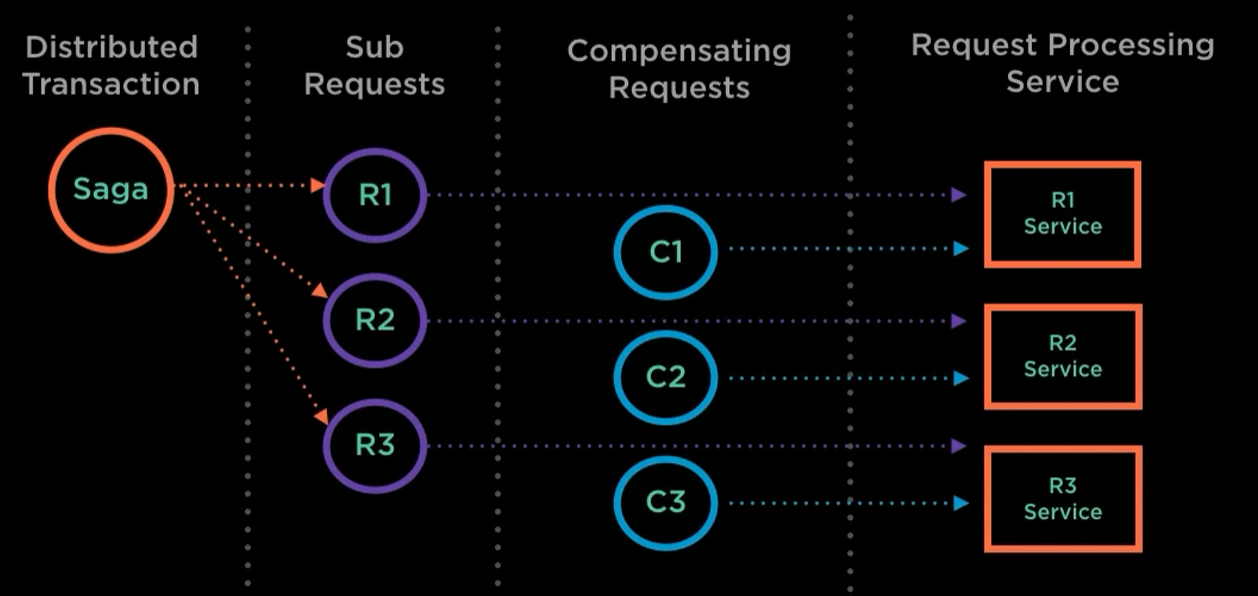
Benefits
- Improved Data Consistency: The Saga pattern provides a mechanism for achieving data consistency in a distributed environment by breaking down transactions into smaller, manageable units called sagas.
- Failure Management: The pattern offers built-in failure management capabilities, allowing for handling failures at the request level. It enables the system to compensate for failed requests and maintain consistency.
- Flexibility and Scalability: Sagas can be designed to handle complex workflows and long-running transactions. They provide flexibility in managing transactions that span multiple services and can be scaled horizontally to accommodate increased demand.
- Loosely Coupled Services: The Saga pattern promotes loose coupling between services, as each service handles its own part of the saga independently. This enhances the modularity and maintainability of the overall system.
- Compatibility with Microservices Architecture: The Saga pattern aligns well with the principles of microservices architecture, providing an approach to handle transactions within a distributed system.
Drawbacks and Considerations
- Lack of Atomicity: Unlike traditional transactions, sagas do not guarantee atomicity across all sub-requests. It means that a saga may have partially completed requests, leading to potential inconsistencies in the system.
- Increased Complexity: Implementing the Saga pattern introduces additional complexity to the system. The coordination of sagas, maintaining the Saga Log, and handling compensating requests require careful design and management.
- Eventual Consistency: Sagas rely on compensating requests to undo the effects of failed or rolled-back requests. This can introduce eventual consistency, where the system may take some time to reach a consistent state.
- Long-Running Transactions: Handling long-running sagas may pose challenges in terms of performance, resource management, and maintaining system responsiveness.
- Saga Execution Coordinator as a Single Point of Failure: The Saga Execution Coordinator plays a crucial role in processing sagas. Its availability becomes critical, and its failure could impact the overall system’s transaction handling.
- Operational Complexity: Managing sagas, monitoring their progress, and ensuring proper error handling can add operational overhead to the system.
Eventual Consistency pattern
It´s time to review the Eventual Consistency as an approach to achieving data consistency in a microservices architecture. Eventual consistency is more of an approach rather than a specific design pattern. It focuses on the idea that data within the system will eventually become consistent, rather than requiring immediate consistency.
This approach is based on the BASE model, which stands for Basic Availability, Soft State, and Eventual Consistency. The BASE model suggests that data updates can be more relaxed, and immediate updates to all data are not always necessary. Slightly stale data that provides approximate answers is acceptable in certain cases. This approach differs significantly from the ACID model, where immediate updates are essential for maintaining consistency.
When considering the CAP theorem, eventual consistency prioritizes availability over consistency. By allowing certain updates to occur in the background and separate from the immediate transaction, the system becomes more responsive. Unlike ACID transactions, the eventual consistency approach does not require locking multiple resources, resulting in improved performance and responsiveness.
The eventual consistency approach is particularly beneficial for handling long-running tasks that would typically slow down ACID-type transactions. Instead of impeding immediate transactions, these tasks can be executed as background processes, ensuring performance and responsiveness are not compromised. It is important to note that the time it takes for data to become consistent using eventual consistency approaches is typically measured in seconds, rather than days, minutes, or hours. This level of consistency achieved within seconds is acceptable considering the performance gains and system responsiveness.
Traditionally, achieving eventual consistency involved data replication at the database level. However, in the microservices world, an event-based approach is more common. Event-based eventual consistency works by raising events as part of transactions and actions. These events are typically raised asynchronously, acting as messages placed on message brokers and queues.
It’s important to note that there are multiple ways to achieve eventual consistency. For instance, in an alternative approach, the web application asynchronously writes a record to a NoSQL database and continues with the transaction. Later, a service picks up the event from the NoSQL database and processes it in the background. The data will eventually become consistent in this scenario as well. In summary :
BENEFITS
- Improved Performance and Responsiveness: Eventual consistency allows immediate transactions to proceed without waiting for all data updates to occur. This enhances the performance and responsiveness of the system, providing a better user experience.
- Scalability: Eventual consistency supports scalability by enabling the system to handle a larger number of concurrent transactions without being blocked by data consistency requirements. This scalability is particularly useful for systems with high transaction volumes.
- Flexibility and Loose Coupling: The eventual consistency approach promotes loose coupling between services. Each service can perform updates independently, reducing dependencies and enabling greater flexibility in service deployment and evolution.
- Fault Tolerance: Eventual consistency helps in maintaining system availability and fault tolerance. By decoupling data updates from immediate transactions, the system can continue functioning even if individual services or components experience failures.
- Support for Long-Running Tasks: Eventual consistency is well-suited for handling long-running tasks that would otherwise impact the responsiveness of immediate transactions. By executing these tasks in the background, system performance and user experience are not compromised.
DRAWBACKs
- Eventual Inconsistencies: The main drawback of eventual consistency is the potential existence of temporary inconsistencies or stale data during the convergence process. It might take some time for all replicas or services to receive and process the updates, leading to inconsistencies that eventually resolve.
- Complexity in Design and Implementation: Implementing eventual consistency requires careful design and consideration of various factors such as data replication, event-driven mechanisms, and handling conflict resolution. This complexity can increase the development and maintenance efforts.
- Trade-Off between Consistency and Real-Time Accuracy: Eventual consistency trades off immediate consistency for improved performance and responsiveness. This trade-off may not be suitable for scenarios where real-time accuracy is critical, such as financial systems or real-time monitoring.
- Additional Effort for Conflict Resolution: In cases where conflicting updates occur, resolving conflicts and maintaining data integrity can be challenging. Implementing conflict resolution strategies and ensuring consistency across replicas or services adds complexity to the system.
- System Monitoring and Testing: Verifying and monitoring eventual consistency can be more challenging compared to strict consistency models. Testing and ensuring the correctness of eventual consistency mechanisms require careful consideration.
Eventual consistency is closely tied to asynchronous communication. The goal is to have the data eventually become consistent in the background, as a fire-and-forget tasks.
That´s all for today, happy building !